Fundamentos de la línea de comandos
Teoría: Estructura de archivos
Cuando empezamos a trabajar con sistemas basados en Unix (como Linux o macOS), una de las primeras cosas que debemos aprender es su estructura de archivos. Esta se ve muy diferente a la que usamos en Windows, así que vale la pena entenderla bien desde el comienzo.
Vamos a recorrer juntos, paso a paso, cómo funciona esta estructura, para que te sientas más cómodo y puedas moverte por ella como todo un pro.
Un árbol para organizarlos a todos
Imaginemos la estructura de archivos como un gran árbol:
🌳 En las ramas tenemos los directorios (lo que en Windows llamamos “carpetas”).
🌳 En las hojas están los archivos (documentos, imágenes, programas, etc.).
Este árbol inicia desde un solo punto: la raíz /. A partir de ahí, todo se organiza en una jerarquía ordenada.
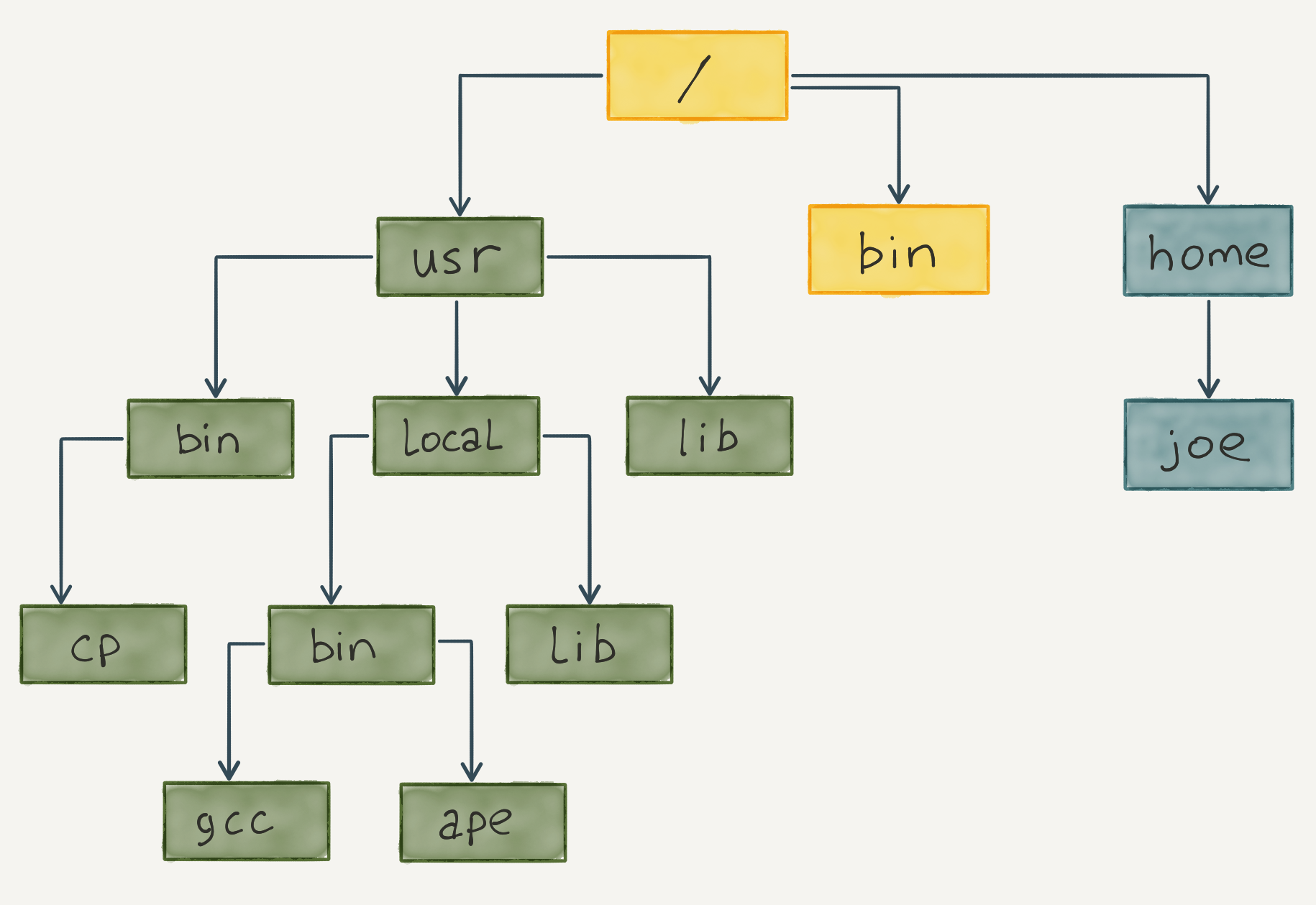
¿Carpetas? Aquí les llamamos directorios
Un detalle importante: en Windows tenemos un árbol diferente por cada disco (C:, D:, etc.). En *nix, solo hay un árbol, y todo vive dentro de él, incluso otros discos y dispositivos.
Por ejemplo:
- Un disco duro externo puede estar en
/mnt/usb1. - La configuración del sistema puede estar en
/etc.
Todo está conectado dentro del mismo árbol.
Ver información sobre archivos
Ya que sabemos qué es un archivo, ¿cómo vemos los detalles?
Usamos el comando stat. Este nos muestra mucha información útil sobre un archivo:
Salida (abreviada):
No te preocupes si no entiendes todos los datos todavía. Iremos explicándolos en otras lecciones.
🎬 Puedes ver este comando en acción:

Cuidado con las mayúsculas
En Windows, los nombres de los archivos no distinguen entre mayúsculas y minúsculas. Por ejemplo, foto.JPG y FOTO.jpg serían el mismo archivo.
Pero en *nix, esto sí importa. Son archivos distintos:
Así que siempre presta atención a cómo escribes los nombres.
Todo es un archivo (casi todo)
En Unix decimos que todo es un archivo. Hasta los directorios. También los dispositivos como teclados, impresoras o discos duros.
✅ Esto tiene una ventaja: desde el punto de vista del sistema operativo y los programas, muchas cosas se controlan escribiendo y leyendo archivos, lo cual simplifica el desarrollo de software.
Algunos ejemplos:
Estructura estándar del sistema: FHS
Aquí van algunos de los más comunes y útiles:
Archivos ocultos
En Windows podemos ocultar archivos marcándolos como invisibles. En Unix es mucho más simple: si un archivo empieza con un punto (.), es oculto.
Ejemplos:
🫥 .bashrc → oculto
😐 documento.txt → visible
Para ver todos los archivos, incluyendo los ocultos, usamos:
Salida posible:
. .. .bashrc .profile archivo.txt
.→ el directorio actual..→ el directorio anterior (nivel superior)
Estos dos aparecen siempre.
Tipos de archivos
En Unix no todo son archivos “normales”. Aquí algunos tipos comunes:
Vamos a ver algunos ejemplos más adelante, cuando comencemos a trabajar con comandos como ln, touch y otros.
Diferencias importantes con Windows
Aquí un resumen de las principales diferencias entre Unix y Windows que ya vimos:
Resumen
- En sistemas Unix, la estructura de archivos es un único árbol con raíz en
/. - Usamos el término "directorio" en lugar de "carpeta".
- Todo, incluso los dispositivos, se maneja como archivos.
- El comando
statnos da detalles de cualquier archivo. - Los nombres distinguen mayúsculas de minúsculas.
- Un archivo oculto empieza con un punto (
.). - Existen diferentes tipos de archivos: regulares, directorios, enlaces, sockets.
- La estructura del sistema sigue un estándar conocido como FHS.
Ahora que tenemos una buena base sobre cómo se organiza el sistema de archivos en Unix, estamos listos para movernos y trabajar en él usando comandos y scripts. ¡Manos a la obra!